Difference between revisions of "Shell scripting tutorial"
| (15 intermediate revisions by 6 users not shown) | |||
| Line 2: | Line 2: | ||
This is a [[shell]] [[scripting]] tutorial. We use the [[bash]] shell as it is standard in most Linux distributions. | This is a [[shell]] [[scripting]] tutorial. We use the [[bash]] shell as it is standard in most Linux distributions. | ||
| − | <pic src=" | + | <pic src="/images/3/36/Bash-scripting-mindmap.jpg" width=70% align=right caption=MindMap /> |
= Hello world = | = Hello world = | ||
| Line 164: | Line 164: | ||
if (( $age >= 21 )); then echo "Let's talk about sex."; fi | if (( $age >= 21 )); then echo "Let's talk about sex."; fi | ||
| − | + | I feel saisifted after reading that one. | |
| − | |||
| − | |||
== common mistakes == | == common mistakes == | ||
| Line 263: | Line 261: | ||
kill -l | kill -l | ||
| − | + | = helpful programs = | |
| + | == awk: read a specific column == | ||
| + | [[awk]] is a program that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can extract columns from a text. Let's imagine you want to use the [[program]] [[vmstat]] to find out how high the CPU user load was. Here is the output from vmstat: | ||
| + | procs -----------memory---------- ---swap-- -----io---- -system-- -----cpu------ | ||
| + | r b swpd free buff cache si so bi bo in cs us sy id wa st | ||
| + | 1 0 0 1304736 190232 885840 0 0 20 8 11 17 1 0 99 0 0 | ||
| + | We see the user load is in colum 13, and we only want to print this column. We do it with the following command: | ||
| + | vmstat 5 | awk '{print $13}' | ||
| + | This will print a line from vmstat all 5 seconds and only write the column 13. It looks like this: | ||
| + | # vmstat 5 | awk '{print $13}' | ||
| + | |||
| + | us | ||
| + | 1 | ||
| + | 1 | ||
| + | 0 | ||
| + | 1 | ||
| + | To store the CPU user load into a variable we use | ||
| + | load=$(vmstat 1 2 | tail -n 1 | awk '{print $13}') | ||
| + | What happens here? First vmstat outputs some data in its first line. The data about CPU load can only be rubbish because it did not have any time to measure it. So we let it output 2 lines and wait 1 second between them ( => vmstat 1 2 ). From this command we only read the last line ( => tail -n 1 ). From this line we only print column 13 ( => awk '{print $13}' ). This output is stored into the variable $load ( => load=$(...) ). | ||
| + | |||
| + | == grep: search a string == | ||
| + | [[grep]] is a [[program]] that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can extract lines that contain a string or match a [[regex]] pattern. Let's imagine you want all external links from www.linuxintro.org's main page: | ||
| + | wget -O linuxintro.txt http://www.linuxintro.org | ||
| + | grep "http:" linuxintro.txt | ||
| + | |||
| + | == sed: replace a string == | ||
| + | [[sed]] is a [[program]] that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can replace a string by another one. Let's imagine you want to print your distribution's name, but lsd_release outputs too much: | ||
| + | # lsb_release -d | ||
| + | Description: openSUSE 12.1 (x86_64) | ||
| + | You want to remove this string "Description" so you replace it by nothing: | ||
| + | lsb_release -d | sed "s/Description:\t//" | ||
| + | openSUSE 12.1 (x86_64) | ||
| + | |||
| + | Once you understand [[regular expressions]] you can use sed with them: | ||
| + | |||
| + | * to replace protocol names for a given port (in this case 3200) in /etc/services: | ||
| + | sed -ri "s/.{16}3200/sapdp00 3200/" /etc/services | ||
| + | * if you have an [[apache]] [[web server]] here's how you get the latest websites that have been requested: | ||
| + | cat /var/log/apache2/access_log | sed "<html><acronym title=substitute>s</acronym>;.*<acronym title="for every line remember a substring that is GET, then a blank, then an unknown count of characters that are not a quote">\(GET [^\"]*\)</acronym><acronym title="the part to be substituted will then be followed by an unknown number of arbitrary characters">.*</acronym>;<acronym title="replace this line by the first remembered part">\1;</acronym></html>" | ||
| + | |||
| + | == tr: replace linebreaks == | ||
| + | [[sed]] is a [[program]] that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can replace a character by another one, even over line breaks. | ||
| + | For example here is how you remove all empty lines from your processor information: | ||
| + | # cat /proc/cpuinfo | while read a; do ar=$(echo -n $a|tr '\n' ';'); if [ "$ar" <> ";" ]; then echo "$ar"; fi; done | ||
| + | |||
| + | == wc: count == | ||
| + | With the command wc you can count words, characters and lines. wc -l counts lines. For example to find out how many semicolons are in a line, use the following statement: | ||
| + | while read line; do echo "$line" | tr '\n' ' ' | sed "s/;/\n/g" | wc -l; done | ||
| + | It lets you input a line of text, counts the semicolons in it and outputs the number. | ||
| + | |||
| + | How does it do this? | ||
| + | |||
| + | It reads lines from your keyboard (while read line). It outputs the line (echo "$line"), but it does not output it in the console. The pipe (|) redirects the output to the input stream of the command tr. The command tr replaces the ENTER ('\ | ||
| + | ') by a space (' '). The pipe (|) redirects the output to the input stream of sed. sed substitutes ("s/) the semicolon (;) by (/) a linefeed (\ | ||
| + | ), globally (/g"). The pipe redirects the output to the input stream of the wc -l command that outputs the count of lines. | ||
| + | |||
| + | == dialog: create dialogs == | ||
| + | Dialog is a command that helps you creating dialogs in the shell. The answers given by the user are send to [[stderr]] and/or influence the command's return code. For example if you run this script: | ||
| + | #!/bin/bash | ||
| + | if (dialog --title "Message" --yesno "Are you having fun?" 6 25) | ||
| + | then echo "glad you have fun" | ||
| + | else echo "sad you don't have fun" | ||
| + | fi | ||
| + | It will display this dialog: | ||
| + | |||
| + | [[File:snapshot-dialog.png]] | ||
| + | |||
| + | This has been taken from http://www.linuxjournal.com/article/2807. Read there for more info. | ||
= See also = | = See also = | ||
Latest revision as of 12:38, 27 December 2020
This is a shell scripting tutorial. We use the bash shell as it is standard in most Linux distributions.
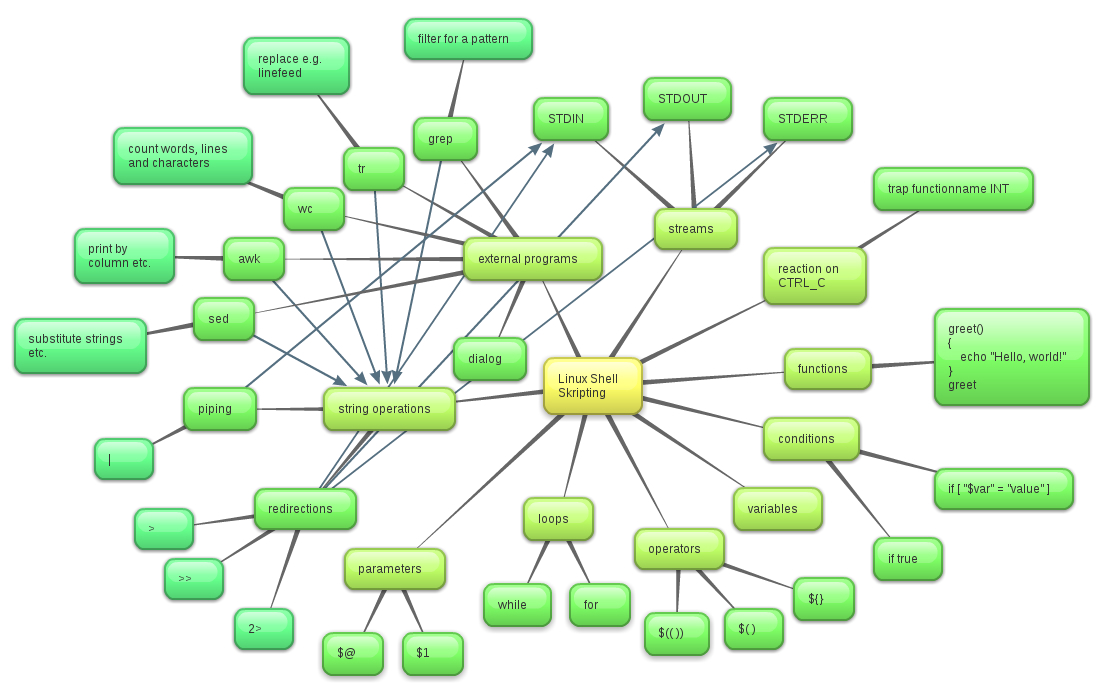 |
MindMap |
Contents
- 1 Hello world
- 2 calling commands
- 3 variables
- 4 parameters
- 5 return codes
- 6 line feeds
- 7 storing a command's output
- 8 conditions
- 9 Redirections
- 10 filling files
- 11 loops
- 12 negations
- 13 sending a process to the background
- 14 forking a process
- 15 functions
- 16 react on CTRL_C
- 17 helpful programs
- 18 See also
Hello world
The easiest way to get your feet wet with a programming language is to start with a program that simply outputs a trivial text, the so-called hello-world-example. Here it is for bash:
- create a file named hello in your home directory with the following content:
#!/bin/bash echo "Hello, world!"
- open a console, enter
cd chmod +x hello
- now you can execute your file like this:
# ./hello Hello, world!
- or like this:
# bash hello Hello, world!
You see - the output of your shell program is the same as if you had entered the commands into a console.
calling commands
In your shell script you can call every command that you can call when opening a console:
echo "This is a directory listing, latest modified files at the bottom:" ls -ltr echo "Now calling a browser" firefox echo "Continuing with the script"
variables
input
To show you how to deal with variables, we will now write a script that asks for your name and greets you:
echo "what is your name? " read name echo "hello $name"
You see that the name is stored in a variable $name. Note the quotation marks " around "hello $name". By using these you say that you want variables to be replaced by their content. If you were to use apostrophes, the name would not be printed, but $name instead.
${}
The ${} operator stands for the variable, there is no difference if you write
echo "$name"
or
echo "${name}"
So what is the sense of this? Imagine you want to echo a string directly, without any blank, after the content of a variable:
echo "if I add the syllable owa to your name it will be ${name}owa"
common mistakes
Note that the variable is called $name, however the correct statement to read it from the keyboard is
read name
It is a common mistake to write
read $name
which means "read a string and store it into the variable whose name is stored in $name"
arrays
How to define an array:
# a=(this is a test)
How to display its members:
# echo ${a[0]}
this
# echo ${a[1]}
is
# echo ${a[2]}
a
# echo ${a[3]}
test
Display the complete array:
# echo ${a[@]}
this is a test
Display its length:
# echo ${#a}
4
parameters
echo "Here are all parameters you called this script with: $@"
echo "Here is parameter 1: $1"
echo "Which parameter do you want to be shown? "
read number
args=("$@")
echo "${args[$number-1]}"
return codes
Every bash script can communicate with the rest of the system by
The return code is 0 if everything worked well. You can query it for the most recent command using $?:
$ echo "hello world"; echo $? hello world 0 $ echo "hello world">/proc/cmdline; echo $? bash: /proc/cmdline: Permission denied 1
In bash, true is 0 and false is any value but 0. There exist two commands, true and false that deliver true or false, respectively:
$ true; echo $? 0 $ false; echo $? 1
line feeds
Let's look at the following script:
read name if [ $name = "Thorsten" ]; then echo "I know you"; fi
Instead of a semicolon you can write a line feed like this:
read name if [ $name = "Thorsten" ] then echo "I know you" fi
And instead of a line feed you can use a semicolon:
read name; if [ $name = "Thorsten" ]; then echo "I know you"; fi
If you want to insert a line feed where you do not need one, e.g. to make the code better readable, you must prepend it with a backslash:
read \
name
if [ $name = "Thorsten" ]
then \
echo "I know you"
fi
storing a command's output
To read a command's output into a variable use $(), backticks or piping.
$()
arch=$(uname -m) echo "Your system is a $arch system."
backticks
arch=`uname -m` echo "Your system is a $arch system."
piping
uname -m | while read arch; do echo "Your system is a $arch system."; done
comparison
The advantage of using backticks over $() is that backticks also work in the sh shell. The advantage of using $() over backticks is that you can cascade them. In the example below we use this possibility to get a list of all files installed with rpm on the system:
filelist=$(rpm -ql $(rpm -qa))
You can use the piping approach if you need to cascade in sh, but this is not focus of this bash tutorial.
common mistakes
Usually unexperienced programmers try something like
uname -m | read arch
which does not work. You must embed the read into a while loop.
conditions
The easiest form of a condition in bash is this if example:
echo "what is your name? " read name if [ $name = "Thorsten" ]; then echo "I know you"; fi
Now let's look closer at this, why does it work? Why is there a blank needed behind the [ sign? The answer is that [ is just an ordinary command in the shell. It delivers a return code for the expression that follows till the ] sign. To prove this we can write a script:
if true; then echo "the command following if true is being executed"; fi if false; then echo "this will not be shown"; fi
empty strings
An empty string evaluates to false inside the [ ] operators so it is possible to check if a string result is empty like this:
tweedleburg:~ # result= tweedleburg:~ # if [ $result ]; then echo success; fi tweedleburg:~ # result=good tweedleburg:~ # if [ $result ]; then echo success; fi success
arithmetic expressions
echo "what is your age? " read age if (( $age >= 21 )); then echo "Let's talk about sex."; fi
I feel saisifted after reading that one.
common mistakes
Common mistakes are:
- to forget the blank behind/before the [ or ] character
- to forget the blank behind/before the equal sign
- see what does "unary operator expected" mean
Redirections
To redirect the output of a command to a file you have to consider that there are two output streams in UNIX, stdout and stderr.
filling files
To create a file, probably the easiest way is to use cat. The following example writes text into README till a line occurs that only contains the string "EOF":
cat >README<<EOF This is line 1 This is line 2 This is the last line EOF
Afterwards, README will contain the 3 lines below the cat command and above the line with EOF.
loops
for loops
Here is an example for a for-loop. It makes a backup of all text files:
for i in *.txt; do cp $i $i.bak; done
The above command takes each .txt file in the current directory, stores it in the variable $i and copies it to $i.bak. So file.txt gets copied to file.txt.bat.
You can also use subsequent numbers as a for loop using the command seq like this:
for i in $(seq 1 1 3); do echo $i; done
Me too! Hope it is working out for you. I was lucky egounh to have one meeting cancelled so I am using that to catch up on things with some much needed desk time - like checking a few blogs :) The rest of the day is fairly full, but at least not stressfull. Enjoy the time to refresh if you get any!!Much love,B
negations
You can negate a result with the ! operator. $? is the last command's return code:
# true # echo $? 0 # false # echo $? 1 # ! true # echo $? 1 # ! false # echo $? 0
So you get an endless loop out of:
while ! false; do echo hallo; done
The following code checks the file /tmp/success to contain "success". As long as this is not the case it continues checking:
while ! (grep "success" /tmp/success) do sleep 30 done
The following code checks if the file dblog.log exists. As long as this is not the case it tries to download it via ftp:
while ! (test -e dblog.log); do ftp -p ftp://user:password@server/tmp/dblog.log >/dev/null echo -en "." sleep 1 done
sending a process to the background
To send a process to the background, use the ampersand sign (&):
firefox & echo "Firefox has been started"
You see a newline is not needed after the &
forking a process
You can build a process chain using parantheses. This is useful if you want to have two instruction streams being executed in parallel:
(find -iname "helloworld.txt") & (sleep 5; echo "Timeout exceeded, killing process"; kill $!)
functions
To define a function in bash, use a non-keyword and append opening and closing parentheses. Here a function greet is defined and it prints "Hello, world!". Then it is called:
greet()
{
echo "Hello, world!"
}
greet
react on CTRL_C
The command trap allows you to trap CTRL_C keystrokes so your script will not be aborted
#!/bin/bash
trap shelltrap INT
shelltrap()
{
echo "You pressed CTRL_C, but I don't let you escape"
}
while true; do read line; done
- Note
- You can still pause your script by pressing CTRL_Z, send it to the background and kill it there. To catch CTRL_Z, replace INT by TSTP in the above example. To get an overview of all signals that you might be able to trap, open a console and enter
kill -l
helpful programs
awk: read a specific column
awk is a program that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can extract columns from a text. Let's imagine you want to use the program vmstat to find out how high the CPU user load was. Here is the output from vmstat:
procs -----------memory---------- ---swap-- -----io---- -system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1304736 190232 885840 0 0 20 8 11 17 1 0 99 0 0
We see the user load is in colum 13, and we only want to print this column. We do it with the following command:
vmstat 5 | awk '{print $13}'
This will print a line from vmstat all 5 seconds and only write the column 13. It looks like this:
# vmstat 5 | awk '{print $13}'
us
1
1
0
1
To store the CPU user load into a variable we use
load=$(vmstat 1 2 | tail -n 1 | awk '{print $13}')
What happens here? First vmstat outputs some data in its first line. The data about CPU load can only be rubbish because it did not have any time to measure it. So we let it output 2 lines and wait 1 second between them ( => vmstat 1 2 ). From this command we only read the last line ( => tail -n 1 ). From this line we only print column 13 ( => awk '{print $13}' ). This output is stored into the variable $load ( => load=$(...) ).
grep: search a string
grep is a program that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can extract lines that contain a string or match a regex pattern. Let's imagine you want all external links from www.linuxintro.org's main page:
wget -O linuxintro.txt http://www.linuxintro.org grep "http:" linuxintro.txt
sed: replace a string
sed is a program that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can replace a string by another one. Let's imagine you want to print your distribution's name, but lsd_release outputs too much:
# lsb_release -d Description: openSUSE 12.1 (x86_64)
You want to remove this string "Description" so you replace it by nothing:
lsb_release -d | sed "s/Description:\t//" openSUSE 12.1 (x86_64)
Once you understand regular expressions you can use sed with them:
- to replace protocol names for a given port (in this case 3200) in /etc/services:
sed -ri "s/.{16}3200/sapdp00 3200/" /etc/services
- if you have an apache web server here's how you get the latest websites that have been requested:
cat /var/log/apache2/access_log | sed "<html><acronym title=substitute>s</acronym>;.*<acronym title="for every line remember a substring that is GET, then a blank, then an unknown count of characters that are not a quote">\(GET [^\"]*\)</acronym><acronym title="the part to be substituted will then be followed by an unknown number of arbitrary characters">.*</acronym>;<acronym title="replace this line by the first remembered part">\1;</acronym></html>"
tr: replace linebreaks
sed is a program that is installed on almost all Linux distributions. It is a good helper for text stream processing. It can replace a character by another one, even over line breaks. For example here is how you remove all empty lines from your processor information:
# cat /proc/cpuinfo | while read a; do ar=$(echo -n $a|tr '\n' ';'); if [ "$ar" <> ";" ]; then echo "$ar"; fi; done
wc: count
With the command wc you can count words, characters and lines. wc -l counts lines. For example to find out how many semicolons are in a line, use the following statement:
while read line; do echo "$line" | tr '\n' ' ' | sed "s/;/\n/g" | wc -l; done
It lets you input a line of text, counts the semicolons in it and outputs the number.
How does it do this?
It reads lines from your keyboard (while read line). It outputs the line (echo "$line"), but it does not output it in the console. The pipe (|) redirects the output to the input stream of the command tr. The command tr replaces the ENTER ('\ ') by a space (' '). The pipe (|) redirects the output to the input stream of sed. sed substitutes ("s/) the semicolon (;) by (/) a linefeed (\ ), globally (/g"). The pipe redirects the output to the input stream of the wc -l command that outputs the count of lines.
dialog: create dialogs
Dialog is a command that helps you creating dialogs in the shell. The answers given by the user are send to stderr and/or influence the command's return code. For example if you run this script:
#!/bin/bash if (dialog --title "Message" --yesno "Are you having fun?" 6 25) then echo "glad you have fun" else echo "sad you don't have fun" fi
It will display this dialog:

This has been taken from http://www.linuxjournal.com/article/2807. Read there for more info.
See also
- bash
- shell
- scripting
- bash operators
- http://en.wikibooks.org/wiki/Bash_Shell_Scripting
- http://ryanstutorials.net/linuxtutorial/scripting.php
- http://wiki.linuxquestions.org/wiki/Bash_tips
- http://wiki.linuxquestions.org/wiki/Bash
- http://linuxconfig.org/Bash_scripting_Tutorial
- http://steve-parker.org/sh/intro.shtml
- http://mywiki.wooledge.org/BashFAQ
- http://mywiki.wooledge.org/BashPitfalls